Ajinkya Koshti

Hi! My name is Ajinkya and I'm a data scientist located in Ames, IA.
I specialize in unstacking business value of data and delayering complex problems with state-of-the-art data science techniques. For more details, check out the About Me section.
View My LinkedIn Profile
This is a fun project that I did to try out the pretrained models on datastream created from google images. It was a good practice in building data pipelines, creating image transforms, importing the pretrained models and optimizing the learning rate.
I searched for images of some of the famous football players on google images and fed the first 200 images to this model to see how well the model is able to train on an uncurated noisy data.
Recognizing players can be an useful application in sport analytics. A lot of in-game metrics like xG and xA scores, heatmaps depend on some kind of deep learning algorithms running in the backend.
Setting up the libraries
This step mounts the google drive in working enironment which would be used as a backend storage.
from google.colab import drive
drive.mount('/content/gdrive')
Drive already mounted at /content/gdrive; to attempt to forcibly remount, call drive.mount("/content/gdrive", force_remount=True).
from fastai.vision import *
import warnings
warnings.filterwarnings("ignore")
Creating data pipeline
ls
[0m[01;34mgdrive[0m/ [01;34msample_data[0m/
cd gdrive/My Drive/fastai_player_recog/
/content/gdrive/My Drive/fastai_player_recog
folder = 'cr'
file = 'cr.csv'
folder = 'messi'
file = 'messi.csv'
folder = 'suarez'
file = 'suarez.csv'
path = Path('data/players')
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
path.ls
<bound method <lambda> of PosixPath('data/players')>
classes = ['cr','messi','suarez']
download_images(path/file, dest, max_pics=200)
for c in classes:
print(c)
verify_images(path/c, delete=True, max_size=500)
cr
messi
suarez
cannot identify image file <_io.BufferedReader name='data/players/suarez/00000070.jpg'>
cannot identify image file <_io.BufferedReader name='data/players/suarez/00000096.png'>
Modeling - Data Transformation
Transforms
path = Path('data/players/')
path
PosixPath('data/players')
transforms = get_transforms()
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=transforms, size=224, bs=32).normalize(imagenet_stats)
data.classes
['cr', 'messi', 'suarez']
data.show_batch(rows=3, figsize=(7,8))

As you can see above, the dataset is uncurated with lot of noisy pictures. For example, the last picture is a sketch. There are several such images that are inaccurate/improper but we shall be using them to induce noise in our models.
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
(['cr', 'messi', 'suarez'], 3, 383, 95)
Training
As seen below, we are able to achieve around 87%-89% accuracy by optimizing the learning rate. If we now remove the noise from the data, we shall quite easily be able to achieve an even higher accuracy. It’d be interesting to see which images are misclassified the most.
learn = cnn_learner(data, models.resnet152, metrics=error_rate)
learn.fit_one_cycle(30)
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.153895 | 0.486600 | 0.147368 | 00:08 |
| 1 | 0.176932 | 0.453679 | 0.147368 | 00:08 |
| 2 | 0.186371 | 0.438741 | 0.136842 | 00:08 |
| 3 | 0.176964 | 0.498095 | 0.126316 | 00:09 |
| 4 | 0.187868 | 0.495250 | 0.157895 | 00:08 |
| 5 | 0.173565 | 0.450809 | 0.147368 | 00:09 |
| 6 | 0.167043 | 0.444867 | 0.115789 | 00:09 |
| 7 | 0.161417 | 0.477105 | 0.178947 | 00:08 |
| 8 | 0.164916 | 0.773907 | 0.168421 | 00:08 |
| 9 | 0.157456 | 0.554971 | 0.189474 | 00:08 |
| 10 | 0.157130 | 0.592353 | 0.136842 | 00:09 |
| 11 | 0.168478 | 0.647615 | 0.136842 | 00:08 |
| 12 | 0.172660 | 0.529567 | 0.168421 | 00:09 |
| 13 | 0.178256 | 0.557514 | 0.157895 | 00:08 |
| 14 | 0.172853 | 0.423964 | 0.168421 | 00:09 |
| 15 | 0.170725 | 0.382557 | 0.115789 | 00:09 |
| 16 | 0.156468 | 0.471120 | 0.147368 | 00:09 |
| 17 | 0.133140 | 0.533500 | 0.136842 | 00:09 |
| 18 | 0.115539 | 0.595399 | 0.147368 | 00:09 |
| 19 | 0.108522 | 0.631604 | 0.136842 | 00:09 |
| 20 | 0.105572 | 0.566845 | 0.147368 | 00:09 |
| 21 | 0.103867 | 0.629708 | 0.157895 | 00:09 |
| 22 | 0.096924 | 0.590672 | 0.147368 | 00:09 |
| 23 | 0.091466 | 0.573798 | 0.136842 | 00:09 |
| 24 | 0.080457 | 0.582823 | 0.136842 | 00:09 |
| 25 | 0.077717 | 0.551564 | 0.136842 | 00:09 |
| 26 | 0.075651 | 0.545016 | 0.126316 | 00:09 |
| 27 | 0.064027 | 0.561220 | 0.126316 | 00:09 |
| 28 | 0.060929 | 0.569121 | 0.126316 | 00:09 |
| 29 | 0.054775 | 0.578649 | 0.126316 | 00:09 |
learn.save('stage-1')
learn.unfreeze()
learn.lr_find(stop_div=False, num_it=200)
<div>
<style>
/* Turns off some styling */
progress {
/* gets rid of default border in Firefox and Opera. */
border: none;
/* Needs to be in here for Safari polyfill so background images work as expected. */
background-size: auto;
}
.progress-bar-interrupted, .progress-bar-interrupted::-webkit-progress-bar {
background: #F44336;
}
</style>
<progress value='18' class='' max='19', style='width:300px; height:20px; vertical-align: middle;'></progress>
94.74% [18/19 02:59<00:09]
</div>
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.029879 | #na# | 00:09 | |
| 1 | 0.039062 | #na# | 00:09 | |
| 2 | 0.040193 | #na# | 00:09 | |
| 3 | 0.038014 | #na# | 00:09 | |
| 4 | 0.036690 | #na# | 00:09 | |
| 5 | 0.050070 | #na# | 00:10 | |
| 6 | 0.065584 | #na# | 00:10 | |
| 7 | 0.091199 | #na# | 00:10 | |
| 8 | 0.370187 | #na# | 00:10 | |
| 9 | 0.688983 | #na# | 00:10 | |
| 10 | 0.859709 | #na# | 00:09 | |
| 11 | 0.963872 | #na# | 00:09 | |
| 12 | 1.173712 | #na# | 00:09 | |
| 13 | 1.679814 | #na# | 00:09 | |
| 14 | 2.981434 | #na# | 00:09 | |
| 15 | 14.075550 | #na# | 00:09 | |
| 16 | 116.549461 | #na# | 00:09 | |
| 17 | 650.312622 | #na# | 00:09 |
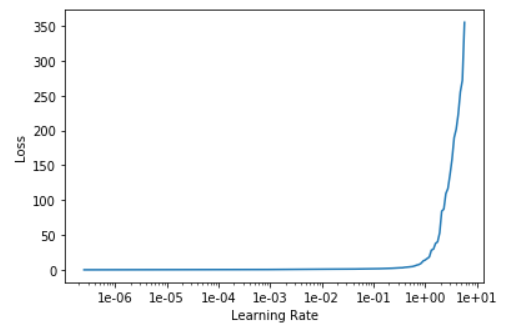 ```python
learn.fit_one_cycle(10, max_lr=slice(1e-03,1e-06))
```
```python
learn.fit_one_cycle(10, max_lr=slice(1e-03,1e-06))
```
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.067066 | 0.845543 | 0.178947 | 00:11 |
| 1 | 0.042421 | 1.085019 | 0.231579 | 00:11 |
| 2 | 0.106151 | 1.190116 | 0.284211 | 00:11 |
| 3 | 0.217121 | 5.310340 | 0.610526 | 00:11 |
| 4 | 0.304309 | 3.054987 | 0.578947 | 00:11 |
| 5 | 0.348517 | 1.629803 | 0.368421 | 00:11 |
| 6 | 0.353958 | 0.877336 | 0.200000 | 00:11 |
| 7 | 0.319123 | 0.604664 | 0.168421 | 00:11 |
| 8 | 0.277269 | 0.568268 | 0.136842 | 00:11 |
| 9 | 0.257772 | 0.594630 | 0.126316 | 00:11 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.199813 | 0.610031 | 0.136842 | 00:08 |
| 1 | 0.169803 | 0.593857 | 0.136842 | 00:08 |
| 2 | 0.145744 | 0.590429 | 0.136842 | 00:08 |
| 3 | 0.139687 | 0.596360 | 0.147368 | 00:08 |
| 4 | 0.137717 | 0.611183 | 0.136842 | 00:08 |
| 5 | 0.122393 | 0.663416 | 0.136842 | 00:08 |
| 6 | 0.124853 | 0.701337 | 0.126316 | 00:08 |
| 7 | 0.136023 | 0.690178 | 0.136842 | 00:08 |
| 8 | 0.134810 | 0.711177 | 0.136842 | 00:08 |
| 9 | 0.133105 | 0.759611 | 0.136842 | 00:08 |
| 10 | 0.122329 | 0.687816 | 0.157895 | 00:08 |
| 11 | 0.121954 | 0.623489 | 0.157895 | 00:08 |
| 12 | 0.108721 | 0.719655 | 0.157895 | 00:08 |
| 13 | 0.099113 | 0.656762 | 0.147368 | 00:08 |
| 14 | 0.094180 | 0.653667 | 0.157895 | 00:08 |
| 15 | 0.089522 | 0.598895 | 0.115789 | 00:08 |
| 16 | 0.082002 | 0.629596 | 0.126316 | 00:08 |
| 17 | 0.093078 | 0.576757 | 0.115789 | 00:08 |
| 18 | 0.085515 | 0.558922 | 0.115789 | 00:08 |
| 19 | 0.082467 | 0.533377 | 0.115789 | 00:08 |
| 20 | 0.076356 | 0.555016 | 0.126316 | 00:08 |
| 21 | 0.073800 | 0.568873 | 0.126316 | 00:08 |
| 22 | 0.078990 | 0.541078 | 0.115789 | 00:08 |
| 23 | 0.076296 | 0.547799 | 0.115789 | 00:08 |
| 24 | 0.077476 | 0.534094 | 0.126316 | 00:08 |
| 25 | 0.071813 | 0.546575 | 0.115789 | 00:08 |
| 26 | 0.065507 | 0.554435 | 0.115789 | 00:09 |
| 27 | 0.063554 | 0.564250 | 0.126316 | 00:08 |
| 28 | 0.058297 | 0.568706 | 0.126316 | 00:08 |
| 29 | 0.055142 | 0.556144 | 0.126316 | 00:08 |

 ```python
interp.plot_confusion_matrix()
```
```python
interp.plot_confusion_matrix()
```
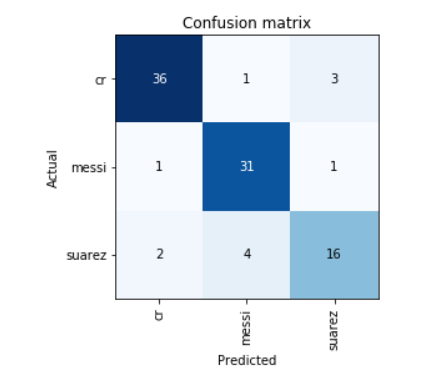 The confusion matrix thus shows that the model is quite adept at classifying the images. It currently shows an accuracy of 87%-89%. The accuracy can further be improved by
- increasing the data
- inceasing the computation effort
- removing the noise from data
```python
```
The confusion matrix thus shows that the model is quite adept at classifying the images. It currently shows an accuracy of 87%-89%. The accuracy can further be improved by
- increasing the data
- inceasing the computation effort
- removing the noise from data
```python
```